细胞内庞大的遗传信息(DNA)指导着细胞的构建、运行与维护。数十年来,科学家们重点解析编码蛋白质的基因,这些“生命执行者”承担着结构、催化、运输和调控等关键功能。权威数据库(如 Swiss-Prot)已收录数万种标准蛋白质,曾让人以为探索接近完成。然而,近期研究揭示,基因组中此前被忽视的大量小型编码序列(smORFs),可翻译成长度不足 150 个氨基酸的微蛋白。这些隐秘的微蛋白正逐渐展现其重要的生物学功能与意义,成为生命科学探索的新前沿。
近期,美国 Salk 研究所团队(Salk Institute)在 BMC Methods 发表文章“ShortStop: a machine learning framework for microprotein discovery”,报道了开源计算工具 ShortStop,这一框架旨在解决微蛋白研究长期存在的核心难题:如何在成千上万个已被检测到有翻译证据的小开放阅读框(smORFs)中,高效筛选出可能具有生物学功能的候选分子。

人类基因组包含超过 300 万个 smORFs,其中多数可能仅产生调控性翻译产物或无功能的肽段,传统验证需要逐一进行功能实验,耗时多年且成本高昂。ShortStop 首次将人工生成的负对照数据与机器学习分类模型结合,在无需实验验证的情况下,通过理化性质特征分析,在测试中达到 90–94% 精度与 87–96% 召回率,从海量 smORFs 中锁定约 8% 具有高度潜力的功能性微蛋白候选。
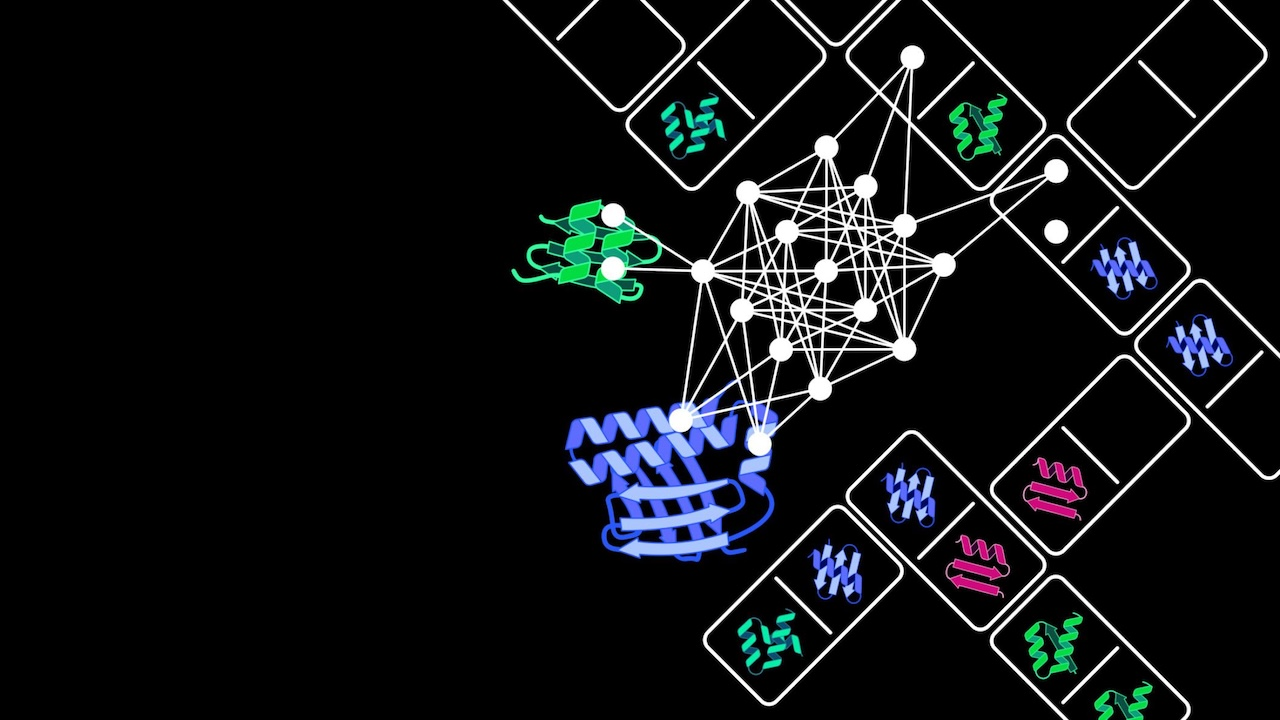
ShortStop 的核心设计在于构建两个参考数据集。一类是 Swiss-Prot Analog Microproteins(SAMs),即来自 Swiss-Prot 数据库的 1,572 个已知功能的微蛋白,包括分泌型和胞内型;另一类是Physicochemically Resembling In Silico Microproteins(PRISMs),即人工生成的序列,保留真实 smORFs 的氨基酸和核苷酸组成及长度,但缺乏序列有序性或进化选择压力,作为非功能肽段的近似负对照。研究团队提取了包括 CTD 结构分布、CKSAAP 局部基序、APAAC 两亲性在内的 128 维生物物理指标,为模型提供结构模式和理化属性的多层信息。
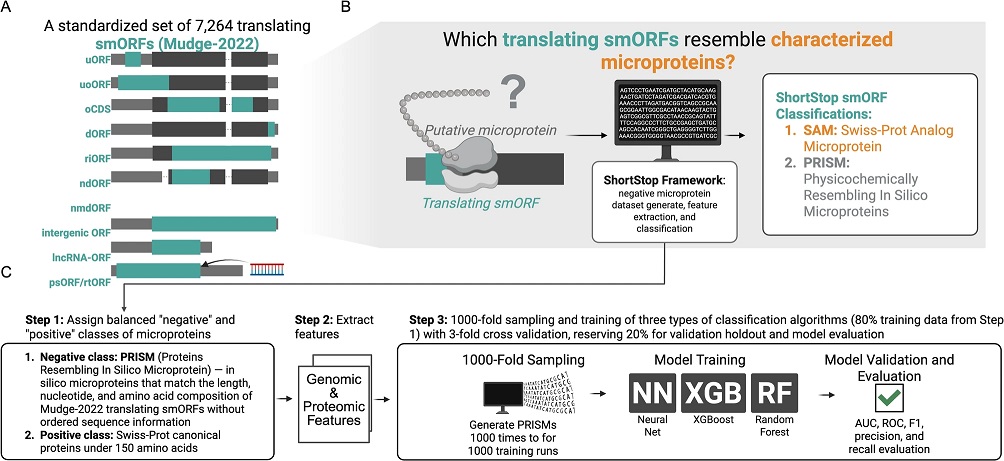
图 | ShortStop 机器学习方法框架
在千次重复采样训练中,研究人员比较了 XGBoost、神经网络和随机森林三种算法,结果显示 XGBoost 在宏平均 AUC(0.970)以及综合精度、召回率和 F1 值上均优于其他模型。特征重要性分析表明,N 端的高亲水性与 C 端的低疏水性是区分功能性与非功能性微蛋白的关键特征,此外亮氨酸-X-亮氨酸(LxL)和甘氨酸-X-精氨酸(GxR)等特征基序在信号肽和 RNA 结合蛋白中常见,也在 SAMs 中显著富集。
将 ShortStop 应用于 Mudge-2022 数据集的 7,264 个翻译 smORFs 时,8% 被归类为 SAMs,92% 为 PRISMs。在 SAMs 分类中,lncRNA 来源的 smORFs 占比达 34.9%。与 PRISMs 相比,SAMs 在 C 端疏水性明显降低,这一特性与减少蛋白酶体降解的趋势一致;N 端在中性 pH 条件下的亲水性显著提高,有助于溶解性和稳定性。
该框架还发现了传统核糖体图谱算法未能识别的微蛋白 StARuMP,其编码序列位于类固醇生成急性调节蛋白(StAR)基因的上游重叠 ORF,因存在多重比对区而被算法忽略。ShortStop 通过 RNA 测序数据将其鉴定为 SAM,后续质谱及免疫检测证实 StARuMP 在睾丸和卵巢中的浓度分别可达 250–500 pg/mg,并通过免疫荧光观察到其在细胞内膜系统的分布,这一定位模式提示其可能参与内膜运输。在肺癌患者样本中,ShortStop 鉴定出 210 个新型免疫肽,其中 116 个在 RNA 层面显著差异表达。其中一个源自胶原蛋白基因 COL1A1 的微蛋白 COL1A1-MP 在肿瘤组织中的表达水平约为正常组织的 4 倍,并在免疫肽组学检测中发现其抗原肽 LAPLVHLV,提示其可能具有肿瘤相关功能价值。
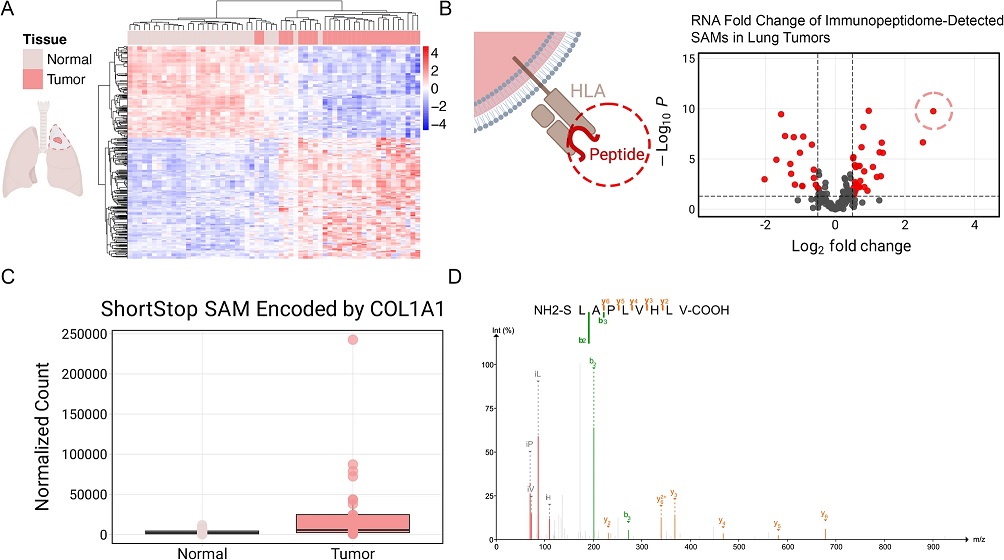
图 | 肺癌患者样本中新型肿瘤相关微蛋白的发现
ShortStop 的优势不仅在于分类精度高,还在于与现有技术的兼容性。它可直接处理 RNA 测序数据,独立于核糖体图谱和起始位点预测工具运行,也可与 TIS Transformer 等方法形成互补,提高潜在功能性微蛋白的捕获率。在质谱富集检测中,ShortStop 还鉴定出数百个未被其他方法报告的候选分子。该工具已于 2025 年 8 月 1 日随论文发表同期开源,显著降低了全球实验室利用既有转录组或蛋白质组数据开展大规模微蛋白挖掘的门槛,为构建疾病相关微蛋白资源库提供了高效路径。
作者强调,PRISM 分类并不意味着这些序列完全无功能,只是表明其理化性质与已知功能性微蛋白差异显著。ShortStop 的分类结果应与其他证据结合使用,以优先安排有限的实验资源。这一方法将微蛋白初筛的候选比例从全部翻译 smORFs 压缩至约 8%,有望显著降低功能验证的工作量,加速合成生物学、疾病机制研究及新型靶点开发的进程。
参考链接:
1.Miller, B., de Souza, E.V., Pai, V.J. et al. ShortStop: a machine learning framework for microprotein discovery. BMC Methods 2, 16 (2025). https://doi.org/10.1186/s44330-025-00037-4
免责声明:本文旨在传递合成生物学最新讯息,不代表平台立场,不构成任何投资意见和建议,以官方/公司公告为准。本文也不是治疗方案推荐,如需获得治疗方案指导,请前往正规医院就诊。

























































































































































































安各洛(深圳)生物科技有限公司 版权所有
